
[Este artículo es un resumen de la charla que ofrecí en el pasado ClinicSEO que tuvo lugar durante el Congreso Web de Zaragoza]
Cuando auditamos una web necesitamos entender muy rápidamente cómo la interpreta Google y qué frenos se encuentra al rastrearla. Por eso hoy te voy a contar por qué y cómo lanzar un crawling para conseguir esta información tan valiosa para valorar nuevos proyectos:
- ¿Es Google capaz de encontrar todas las páginas de contenido de la web?
- ¿Estamos encontrando más o menos páginas de las que realmente existen?
- ¿Hemos generado contenido duplicado?
- ¿Son coherentes los títulos y encabezados con los objetivos de la web?
- ¿La web responde rápido o lento?
Encontrar las páginas duplicadas
Empiezo creando un nuevo proyecto en OnCrawl y lo enlazo con Google Analytics y Google Search Console. Es importante marcar un límite inicial de páginas a recorrer que signifique aproximadamente unas cuantas veces el total de páginas teórico de la web. Si no marcamos ningún límite nos podemos encontrar con webs aparentemente pequeñas que consuman decenas o cientos de miles de urls, que nos supondrá un coste mucho más elevado y una mayor inversión de tiempo que además es innecesaria para empezar a encontrar errores y corregir problemas de la web.
Aquí vemos un ejemplo de web que tenía teóricamente unas 15.000 páginas, pero que durante el primer análisis nos crawlea 20.000, que es el límite que marqué para ese proyecto:
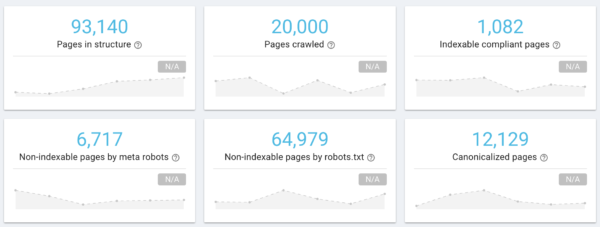
Resumen del crawl realizado, vemos que hay muchas más páginas de las esperadas. Que si dejamos el crawling sin límite seguirían aumentando
¿Qué tenemos que hacer en esta situación? Primero de todo debemos encontrar dónde se generan esas páginas extra, y en OnCrawl es tan rápido como ir a la sección de contenido duplicado para ver los grupos de páginas con muchos duplicados:
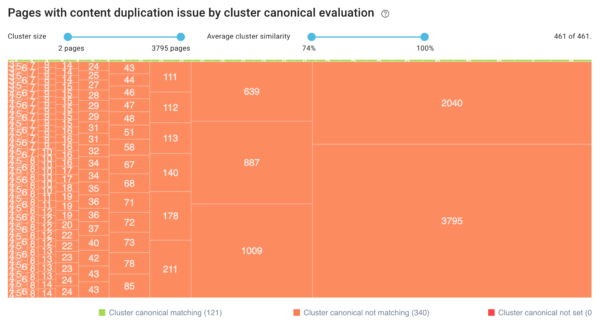
Rápidamente vemos que hay grupos de páginas con muchos duplicados (3795, 2040 etc…)
Cuando pulsamos en cada cluster (los números que vemos en la captura) podemos ver el detalle de cada url duplicada. En este caso, nos damos cuenta de que los duplicados que Google estaría rastreando corresponden a las distintas formas de filtrar y listar los productos en un ecommerce:
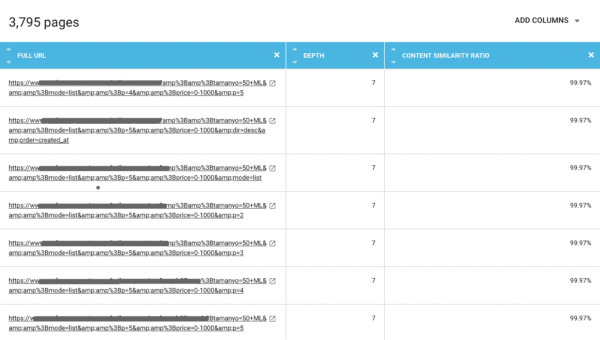
los filtros de precio, mode, order etc crean cientos de páginas con el mismo contenido.
Eliminar lastre del crawling
Antes de seguir con el crawling vamos a eliminar todas esas páginas duplicadas que nos impide ver la foto real de la web. Para ello, creamos un robots.txt virtual que evitará que OnCrawl pase por todas esas páginas que ya luego corregiremos para que no molesten al crawler de Google. Desde OnCrawl podemos añadir un robots.txt que se incluye al que tenemos actualmente en la web que nos permite decir qué filtros y parámetros nos estorban. En este caso añadí estos parámetros:
- Disallow: /*dir=* #no solicitará ninguna url que contenga «dir=»
- Disallow:/*price:* #no solicitará ninguna url que contenga «price:»
- Disallow: /*order=* #no solicitará ninguna url que contenga «order=»
- Disallow: /*mode=list* #no solicitará ninguna url que contenga «mode=list»
Hecho esto lanzamos un nuevo crawl con el virtual robots.txt, pero en esta ocasión si que veremos que cuando el crawling acaba nos muestra un número de páginas similar al que esperábamos que tuviera ese proyecto.
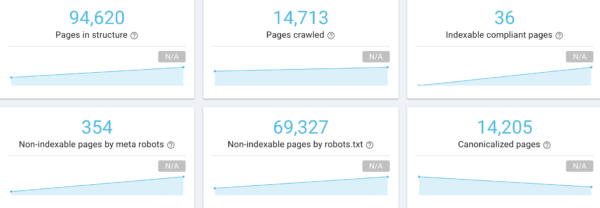
El crawling termina en 14.713 páginas
Analizamos las velocidades de carga
Es imposible analizar una web con 15.000 páginas sin utilizar: con un crawler conseguiremos rápidamente información sobre qué ve Google en nuestra web. De los distintos reports y agrupaciones de datos que nos da OnCrawl rápidamente revisamos los de velocidad de carga de las páginas:
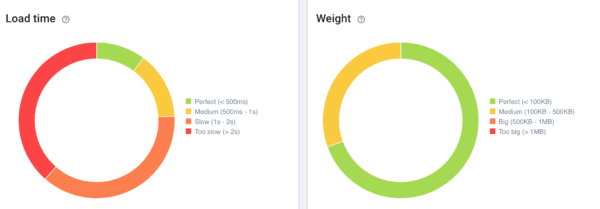
Nos muestra el tiempo de carga del html y el peso del html del conjunto de páginas. Pulsando en las franjas rojas podemos ir directamente al data explorer para ver la lista de páginas.
En muchos proyectos nos puede pasar que algunas secciones de la web tengan una carga rápida y otras tengan una más lenta. Con los clusters de OnCrawl podemos ver en qué secciones tenemos más problemas de velocidades de carga:
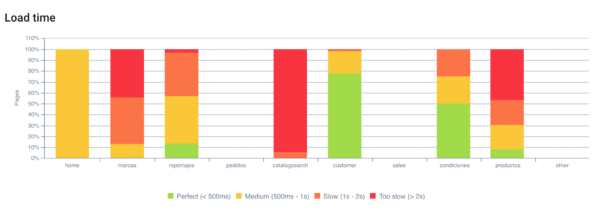
Vemos que en el catalogsearch y productos es donde los tiempos de respuesta de la web son más elevados.
Si la web, de media, tiene una carga rápida pero las páginas que queremos posicionar son lentas no cumpliremos con nuestro objetivo. Nos puede pasar, cómo me he encontrado en algunos casos, que la página de un producto tarde muchíiiiisimo en cargar porque tiene muchos productos relacionados, mientras que otros productos de la misma web cargan razonablemente bien. En estos casos sería imposible detectar este problema sin un crawling que nos lleve a las páginas que detecta cómo lentas, en el caso de OnCrawl, sólo tenemos que pulsar encima de cada franja de color para ir viendo directamente las páginas afectadas en directo. También nos seria útil el data explorer, el filtro que podemos incluir para detectar páginas que tardan más de x segundos en cargar.
Páginas huérfanas
Otra de las circunstancias comunes en los crawlings es que nos encontremos con páginas huérfanas. Las páginas huérfanas, cómo nos explican en el blog de OnCrawl, son esas páginas que existen y reciben tráfico pero que no aparecen enlazadas desde la web que es rastreada por Google.
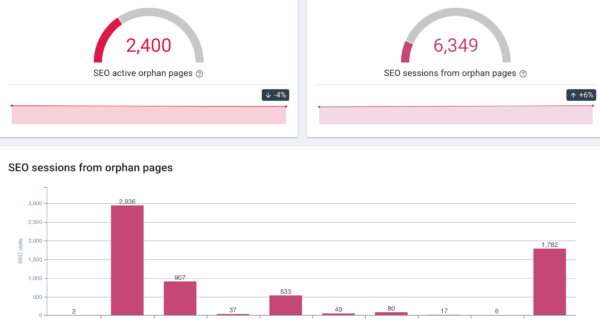
miles de urls en este proyecto estaban recibiendo tráfico desde Google pero sin estar enlazadas en la web.
Descubrir por qué no están enlazadas y qué hacer con ellas es crítico para mejorar la presencia online de cualquier proyecto. Si una url no está enlazada internamente, no se podrá acceder a ella desde la home y es muy posible que Google la acabe arrinconando y olvidando en su rastreo.
Conseguir una evolución positiva
Ya tenemos una primera aproximación del proyecto y sabemos cómo interactúa Google con ella, si la recorre o no, cómo lo hace, etc. Ahora debemos empezar a mejorar el proyecto para conseguir una evolución positiva tanto en datos macro cómo en resultados. Con OnCrawl podemos ver una pequeña gráfica para muchos de los valores que nos muestra la evolución respecto anteriores crawls realizados en el mismo proyecto:

gráficas de evolución en número de páginas
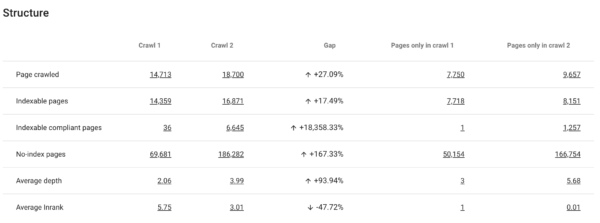
Para ver cómo nos afectan las modificaciones que hemos realizado en el crawling podemos usar el Crawl over Crawl, que nos compara datos de los dos crawls para ver si hemos conseguido el resultado esperado o si deberíamos revisar los cambios antes de que Google los procese.
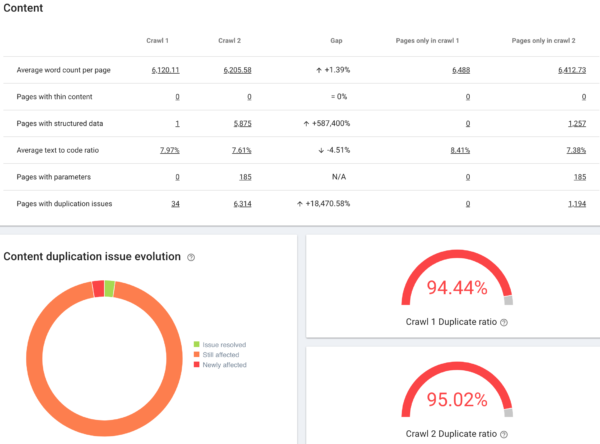
En futuros posts profundizaré más en esta herramienta de crawling, pero por ahora te dejo con una de sus opciones que me soluciona problemas que antes me costaba horas de encontrar y solucionar: el data explorer. Esta herramienta me permite buscar todas las urls que cumplen con todos los criterios que se me ocurra buscar, y es tremendamente interesante combinado con el scraping, que nos da un arma genial para entender los proyectos de gran envergadura con miles o cientos de miles de urls.
Scraper de OnCrawl, para añadir a los datos que tienes de una url cualquier información estructurada del proyecto como el precio, disponibilidad, etc
Está bien como hacer el crawler con el robots virtual pero si lo tienes mal ¿como solucionas el problema? ¿poniendo un robots.txt igual que has subido como virtual?
Gracias por comentar.
Si no has lanzado la web poner el robots.txt que evite la visita de google a esas páginas es lo correcto. Si la web ya está lanzada y Google ha indexado todas esas páginas de think content lo primero que tienes que hacer es conseguir desindexarlas (con meta robots no index o desde GSC). Y una vez desindexadas las bloqueas también en el robots.txt para ahorrar crawl budget.
Está chula la herramienta, yo la probé en su día y mola sobre todo para tener centralizada toda la información que necesitas para SEO (incluyendo las páginas que Google rastrea más de tu sitio y demás). Pero es un poco cara cuando tienes varios proyectos. ¿Tienes algún descuento para comprarla?
Tienes un free trial en https://app.oncrawl.com/trial Es cara más que por varios proyectos si tienes muchas urls a crawlear al mes. Y comparada con otras similares es de las más económicas.